nvsp.in Online Registration of Voter ID Card Form 6 : National Voter’s Service Portal
Organisation : National Voter’s Service Portal
Facility : Apply Online for Registration of New User Form-6
Applicable For : All India
Home Page : https://www.nvsp.in/
Contents
NVSP Form-6 Online Registration
Follow the below procedure to file Form 6. Form 6 is used for Inclusion of Name in Electoral Roll for First time Voter OR on Shifting from One Constituency to Another Constituency.
Related / Similar Service :
NVSP Apply Online for Objection on Inclusion of Name Form 7
Who can file Form-6?
A. An Indian citizen who has attained age of 18 years or more on the first day of January of the year with reference to which the electoral roll is being revised.
B. A person shifting his / her place of ordinary residence outside the constituency in which he / she is already registered.
When Form-6 can be filed?
The application can be filed throughout the year. During the revision of electoral roll, it can be filed after draft publication of electoral roll of the constituency. The application is to be filed within the specific period.

Only one copy of the application is to be filed during the revision programme. During non-revision period, application must be filed in duplicate.
This video is step by step guide to Apply Online for Registration of New User Form-6 :
Where to file Form-6?
A. During revision period, the application can be filed at the designated locations where the draft electoral roll is displayed as well as the offices of Electoral Registration Officer and Assistant Electoral Registration Officer of the constituency.
The application can also be filed online on the website of Chief Electoral Officer of the State concerned.
B. When revision programme is not going on, the application can be filed only with the Electoral Registration Officer or can be filed online.
How to Fill?
Logon to the NVSP website and Click on the Apply online for registration of new voter link
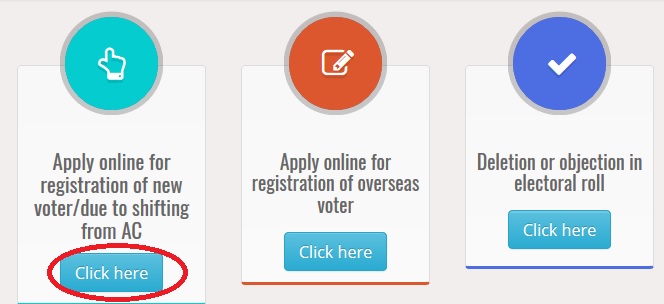
Follow the simple steps to complete your registration. Before you are applying first Select your Language
Step 1 : Select State *
Step 2 : Select District
Step 3 : Select Assembly/Parliamentary Constituency
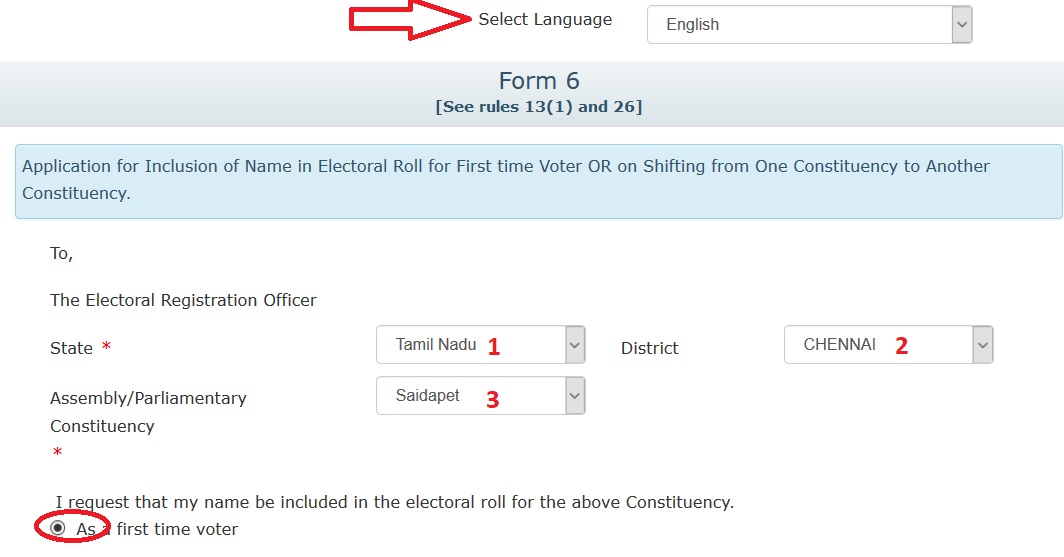
Step 4 : Enter Mandatory Particulars
Step 4.1 : Enter Name *
Step 4.2 : Enter Surname (If any)
Step 4.3 : Enter Name of Relative of Applicant *
Step 4.4 : Enter Surname of Relative of Applicant
Step 4.5 : Enter Type of Relation *
Step 4.6 : Enter Age [as on 1st January of current calendar year] * Or
(f)Date of Birth (in DD/MM/YYYY format)(if known) *
Step 4.7 : Select Gender of Applicant *
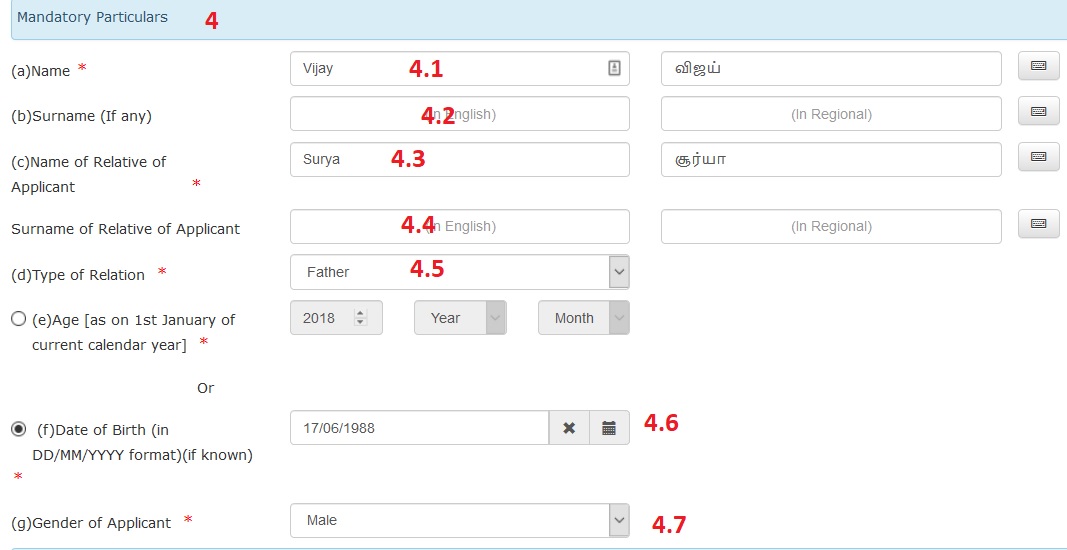
Step 5 : Enter Current address where applicant is ordinarily resident
Step 5.1 : Enter House No & House Name
Step 5.2 : Enter Street/Area/Locality *
Step 5.3 : Enter Town/Village *
Step 5.4 : Enter Post Office *
Step 5.5 : Enter Pin Code *
Step 5.6 : Select State/UT *
Step 5.7 : Select District *. Click Permanent address of applicant same as Current Address
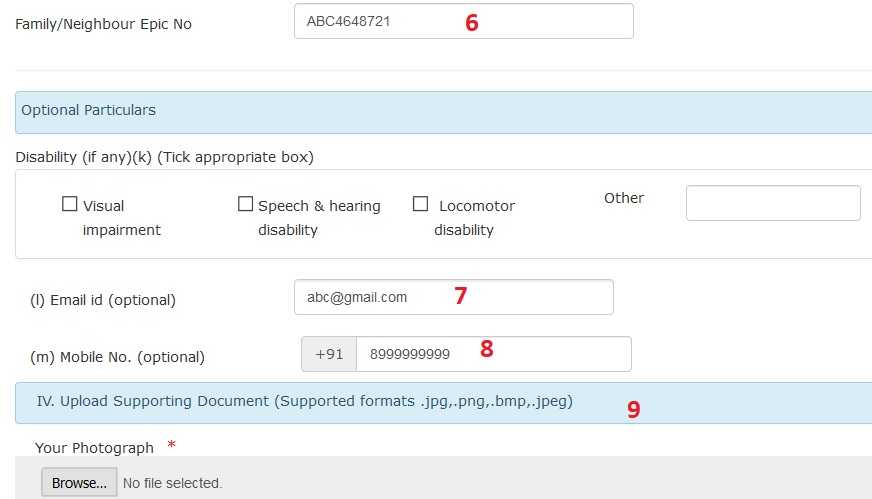
Step 6 : Enter Family/Neighbour Epic No
Optional Particulars :
Disability (if any)(k) (Tick appropriate box)
i. Visual impairment
ii. Speech & hearing disability
iii. Locomotor disability
iv. Other
Step 7 : Enter Email id (optional)
Step 8 : Enter Mobile No. (optional)
Step 9 : Upload Supporting Document
Step 10 : Enter Town/Village
Step 11 : Select State *
Step 12 : Select District *
Step 13 : I am ordinarily resident at the address given at (h) above since Date *
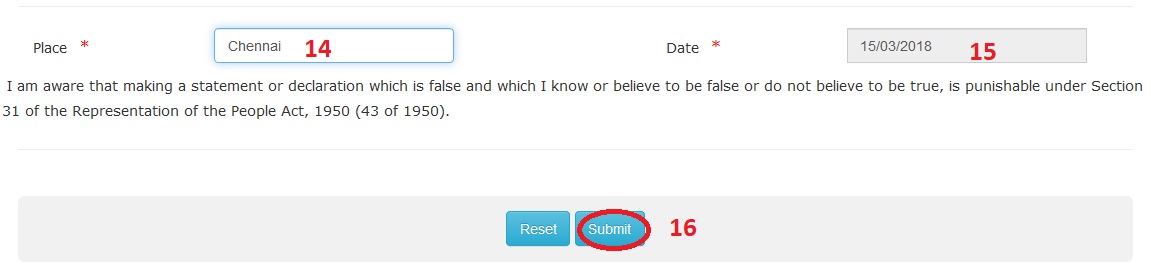
Step 14 : Enter Place
Step 15 : Enter Date
Step 16 : Click Submit button
iam getting error while submitting form 6 for change of constituency.
CAN I SUBMIT FORM 6 FOR NEW VOTER USING MY LOGIN NAME
form 6 is not opeing how to apply voter id
I have successfully filled and submitted form number 6 online. After that, what should I do? & When will I get my voter ID card & Where?
Form 6 is not opening.
Please tell me, how to get and fill age declaration form online?
Under ‘Declaration’ of Form 6 Online, ‘State’ and ‘District’, are not listed in Drop-Down Menu, for those borne in KARACHI then in Undivided India prior to Partition in 1947. Nor, any provision is there to write/insert. By clicking SUBMIT button, no acknowledgement is registered. Please clarify how to solve this problem?
I want to apply online for change of address. My card number is ZBG4519765.
I want to verify my ID fpp2470508.
I have filled form 6 for my Son’s name to be enrolled in the list. Even after successful filling-up, attaching proper documents as per conditions stated, it got upload 100% but failed to generate application number. I tried 3/4 times. Please look into the matter.
Please suggest, ,how to get family EPIC number, also the district selection option is not allowing.
I want to apply for new voter card. What is the last date of online form 6 in Arunachal Pradesh?
I don’t have voter card. What can I do to apply online ?
New Voter Registration :
Go to the link of NVSP website as given in the post & Then go to the “Apply Online For Registration of New Voter/Due To Shifting From AC” link provided there.
(or)
You can use the “Apply Online” link given in the above post.
I have applied for my voter’s Id card. Till now I didn’t get it. Please tell me when I can get my voter’s Id card.
PLEASE HELP ME FOR ONLINE VOTER ID REGISTRATION.
I am not able to get the link of Form 6. I want to apply new voter’s Id for me and my husband.
I have no ID card but my name is present in the voter list.
I want to verify. My id is UWP9032525.
I already have right of vote but there is no id proof. Please approve.
I want to verify my voter ID NAY0605055.
Can I apply aadhaar card as a proof?
I have applied for voter Id Online. When I check status it is showing submitted.
How to verify my voter id status by number?
Which state you belong to?
Form 6A asks for personal sensitive information like passport number, visa etc. But the site is not secured. Why is the site using http instead of https?
How to get my registration number in online from 6?
I guess after you complete applying you will receive application number. You can use it for tracking purpose.
How to upload the identity proof for this that is not possible in this application?
For what purpose you need to upload id proof?
I have already right to vote but no Id proof.
I have film form no 6 but after filing shows message as file is so large
I have already right of vote but no Id proof. Please approve
This is a best site for common people.